Eine Multiprozessorumgebung unterscheidet sich aus Sicht des Garbage Collectors von einer Uniprozessorumgebung und stellt somit besondere Anforderungen an die Implementierung des Collectors. Dabei sind die folgenden 3 Ausgangsprobleme zu beachten:
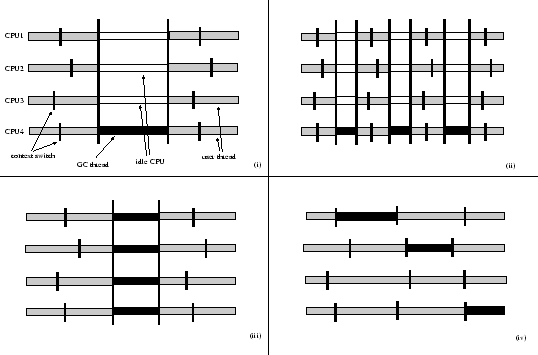
Abbildung 4.5 illustriert Ausgangsproblem 1 am Beispiel einer Umgebung mit vier Prozessoren. In der Teilabbildung (i) findet eine klassische ,,Stop-the-World`` Collection statt - entsprechend wird während der Garbage Collection nur ein Prozessor verwendet, während die verbleibenden Prozessoren ungenutzt bleiben4.4. Das im vorherigen Abschnitt dargestellte inkrementelle Verfahren (Teilabbildung (ii)) verkürzt zwar die Pausen, die durch Garbage Collection entstehen, die Auslastung der Prozessoren verbessert sich jedoch nicht.
 |
Um einen Garbage Collector zu implementieren, der die obigen Probleme berücksichtgt bieten sich prinzipiell zwei orthogonale Ansätze an4.5:
Bei der parallelen Garbage Collection handelt es sich also um die Parallelisierung des sonst sequentiellen Vorgangs der Garbage Collection. Dabei ist zu beachten, daß eine effiziente dynamische Lastverteilung zwischen den arbeitenden Threads vorgenommen werden muß. Diese Lastverteilung erfordert natürlich Kommunikation zwischen den beteiligten Threads, wobei die hierzu notwendige Synchronisierung aber wegen Ausgangsproblem 2 möglichst gering gehalten werden muß. Weiterhin muß zuverlässig und effizient erkannt werden, wann die Garbage Collection terminiert.
Die naive Implementierung eines parallelen ,,Mark-Sweep``-Algorithmus - also eines nicht-bewegenden Verfahrens - ist von vergleichsweise geringer Komplexität. Probleme treten hier überwiegend bei der effizienten Implementierung der Lastverteilung, der Enderkennung und der Verwaltung der Freispeicherliste auf.
[Endo et al., 1997] verwenden zur Lastverteilung sogenannte ,,Stealable Mark Queues`` - jeder andere Prozessor kann Objekte aus der aus der Markierungsliste eines anderen Prozessors stehlen, wenn er keine Arbeit mehr hat.
Die Nachteile eines ,,Mark-Sweep``-Algorithmus sind bekannt, weshalb ein paralleles kompaktierendes Verfahren wünschenswert wäre. Dieses ist aufwendiger zu realisieren, da verhindert werden muß, daß ein Objekt von mehreren Prozessoren ,,gleichzeitig`` bewegt wird.
[Kolodner and Petrank, 1999] versuchen, diese Probleme mit Hilfe einer parallel implementierten ,,Copying Collection`` zu lösen. Da hier jedoch Objekte bewegt werden, zieht dies einen hohen Synchronisierunsaufwand nach sich. Dieser wird gemindert, indem Speicher in ,,To-Space`` blockweise angelegt wird: eine synchronisierte Allokationsoperation wird daher nicht für jedes evakuierte Objekt ausgeführt. Unmittelbar bei der Evakuierung eines Objektes ist beim Eintragen des Vorwärtsverweises in ,,From-Space`` jedoch CAS oder eine vergleichbare Operation notwendig.
Die Threads des Garbage Collectors kommunizieren über verschiedene Listen miteinander, um eine Lastverteilung zu erzielen. Eine Lastverteilung ist essentiell: [Endo et al., 1997] vermelden, daß eine naive Verteilung der Wurzelreferenzen auf 64 Prozessoren lediglich eine Beschleunigung der Collection um den Faktor 3 ergeben hat. Die beschriebene Lastverteilung über ,,Stealable Mark Queues`` erreicht hingegen eine Beschleunigung um den Faktor 28.
Die vielversprechenden Algorithmen im Bereich der nebenläufigen Garbage Collection für Multiprozessorsysteme beruhen überwiegend auf Dijkstras ,,On-The-Fly``-Verfahren und gehören damit zur Klasse der ,,Mark-Sweep``-Algorithmen ohne Heap-Kompaktierung. Ein nebenläufiger und kompaktierender Algorithmus, der als bescheiden zu bezeichnen wäre, scheint schwer realisierbar, da im Prinzip jede lesende oder schreibende Operation der Anwendung mit dem Garbage Collector synchronisiert werden müßte. Dies ist wegen Ausgangsproblem 2 inakzeptabel ist.
[Doligez and Leroy, 1993] gelingt es durch die Ausnutzung einer Spracheigeschaft von ML, einen generationalen und nebenläufigen Garbage Collector zu implementieren. Dabei erhält jeder Thread einen eigenen Heap, auf dem ausschließlich unveränderliche Objekte abgelegt werden - dieser Heap stellt die jüngste Generation dar. Weiterhin existiert ein globaler Heap, auf dem veränderliche Objekte sowie Kopien von Objekten, die eine Garbage Collection überstanden haben, abgelegt werden. Referenzen von der alten in einen junge Generation läßt der Algorithmus nicht zu - stattdessen wird das zugewiesene Objekt mitsamt seiner transitiven referentiellen Hülle in die alte Generation kopiert. Diese wird von einem nebenläufigen Garbage Collector bearbeitet. Der Algorithmus ist darauf angewiesen, daß der Compiler veränderbare und unveränderliche Objekte unterscheiden kann - dies ist in funktionalen Sprachen möglich, für die Implementierung einer objektorientierten Sprache eignet sich der Algorithmus jedoch nicht.
Der Algorithmus von [Doligez and Gonthier, 1994] stellt eine Verallgemeinerung des obigen Algorithmus dar, denn die Trennung von veränderlichen und unveränderlichen Objekten entfällt - damit aber auch die Generationen. Objekt-Allokation findet von vorneherein in dem globalen Speicher statt. Somit handelt es sich also um eine multiprozessorfähige Erweiterung von Dijkstras ,,On-the-Fly``-Algorithmus. Zu keinem Zeitpunkt werden alle Threads auf einmal angehalten - statt dessen synchronisiert der Garbage Collection sich mit jeweils mit einzelnen Threads. Sobald diese Synchronisation mit allen Threads durchgeführt worden ist, sprich wenn alle Wurzelobjekte markiert wurden, führt der Garbage Collector nebenläufig den ,,Mark-Sweep``-Algorithmus durch. In dieser Phase habe Anwendungs-Threads dem Garbage Collector durchgeführte Veränderungen am Speicher mitzuteilen. Dies kann jedoch ohne jegliche Synchronisation inline in einer ,,Write Barrier`` ausgeführt werden. Außerhalb der Garbage Collection braucht die Anwendung keine zusätzlichen Operationen auszuführen.
[Domany et al., 2000] haben diesen Algorithmus für Java implementiert. Dabei wird die Technik aus [Demers et al., 1990] verwendet, um Generationen zu implementieren, ohne Objekte zu bewegen. Es handelt sich also um ein multiprozessorfähiges ,,On-the-Fly``-Verfahren mit Generationen und ohne Kompaktierung. Ihre Messungen beziehen sich allein auf den Geschwindigkeitsgewinn, der durch die Verwendung von Generationen erzielt wird (zwischen 4% Verlust und 25% Gewinn) - ein Vergleich mit einem herkömmlichen ,,Stop-the-World``-Algorithmus wurde jedoch nicht gemacht.
Die Ansätze der parallelen und nebenläufigen Collection sind prinzipiell kombinierbar, d.h. ein paralleler und nebenläufiger Collector ist durchaus denkbar. Da in üblichen Systemen die Garbage Collection einen Anteil von 2-5 % an der Gesamtlaufzeit des Systems einnimmt, scheint eine Parallelisierung einer nebenläufigen Collection in Systemen mit mehr als 20 Prozessoren wünschenswert. Ohne Parallelisierung könnte der Garbage Collector nicht mit der Anwendung schritthalten, und es würden Pausen entstehen.
Prinzipilell läßt sich feststellen, daß die Techniken der nebenläufigen Garbage Collection insbesondere aufgrund fehlender Kompaktierung noch nicht ausgereift genug sind, um an die Leistungsfähigkeit aktuell verwendeter generationaler Algorithmen heranzureichen. Hingegen scheint sich die Technik der parallelen Garbage Collection gut in einen herkömmlichen Kontext einbinden zu lassen und dürfte damit schneller in modernen multiprozessorfähigen virtuellen Maschinen zu finden sein.