Sowohl das n:1- als auch das 1:1-Modell entsprechen jeweils einer Sichtweise von Nebenläufigkeit als Abstraktions- oder Parallelisierungsmechanismus. Ihre Nachteile verhindern den Einsatz im jeweils anderen Kontext:
Zweistufige Implementierungen versprechen Abhilfe durch eine Kombination beider Modelle. Diese Implementierungen nutzen eine auf [Anderson et al., 1991] basierende zweistufige Architektur, in der sowohl Threads auf Anwendungsebene als auch LWP zum Einsatz kommen. Viele UNIX-Derivate (z.B. AIX, IRIX, Solaris und Tru64 Unix) setzen diese Architektur für ihre Implementierung der POSIX Thread-Schnittstelle um, da sie flexibel über verschiedene Anwendungsprofile skaliert [Vetter et al., 1999,Sun Microsystems, 2000c,Compaq, 1999]. Interessanterweise scheinen erst Java-Implementierungen diese Bibliotheken an ihre Grenzen bringen -- eine Zahl von Betriebssystemupdates der Solaris-Thread-Bibliothek, die für den fehlerfreien Betrieb der JVM erforderlich sind, ist ein deutlicher Beleg für diese These [Sun Microsystems, 2000d].
Schlüssel der Architektur ist die Abbildung von vielen im user space implementierten Threads auf eine kleine Anzahl von LWP. Maximale Parallelität wird bereits erreicht, wenn die Zahl der LWP gewählt wird als
| k = p + i | (5.1) |
(k: Zahl der LWP, p: Zahl der Prozessoren, i: Zahl der zu diesem Zeitpunkt aktiven I/O-Operationen). Gleichzeitig ist sichergestellt, daß Kontextwechsel zwischen im user space implementierten Threads keinen Aufruf des Betriebssystemkerns erfordern und daher sehr leichtgewichtig sind.
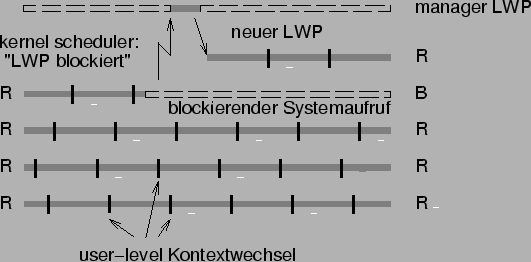
Um diese Zahl zu ermitteln, müssen der Kern-Scheduler und Anwendungs-Scheduler miteinander kommunizieren, insbesondere muß dem Anwendungs-Scheduler das Blockieren eines LWP mitgeteilt werden, damit dieser einen neuen LWP anfordern kann (siehe Abbildung 5.1: Im Idealfall sind genau p (hier 4) LWP im Zustand ,,Running``). Bietet der Betriebssystemkern keine entsprechende Kommunikationsschnittstelle, so kann vereinfachend eine fixe Zahl von LWP genutzt werden, die in etwa dem erwarteten Wert von k entspricht.
Für Implementierungen virtueller Maschinen, die zu einer hohen Zahl von Threads skalieren und dabei mehrere Prozessoren nutzen sollen, sollte folglich die Wahl auf eine zweistufige Architektur fallen. VM-Implementierungen, die Threads mit Hilfe einer solchen Thread-Bibliothek des Betriebssystems realisieren, profitieren automatisch von genannten Vorteilen. Dazu zählen beispielsweise die Solaris-Versionen der Sun Classic VM [Sun Microsystems, 2000a] mit native threads Option, der Sun HotSpot-VM [Sun Microsystems, 1999], und der Sun Research VM [Sun Microsystems, 2000e] sowie das IBM JDK auf AIX [IBM, 2000]. Linux-JVMs, die Threads direkt durch LinuxThreads [Leroy, 1997] realisieren, gehören nicht dazu, da der Linux-Kernel kein Two-Level-Scheduling unterstützt [Bryant and Hartner, 2000]. Gleiches gilt für Java-Maschinen, deren Threads direkt auf die LWPs von Windows NT abgebildet werden.
Insbesondere für die letzten beiden Betriebssysteme existieren mehrere Java-Implementierungen mit VM-basierten Anwendungs-Schedulern. Hierzu zählen JRockit von Appeal [Appeal, 2000] sowie das Laufzeitsystem des NaturalBridge BulletTrain Compilers [NaturalBridge, 2000]. Die IBM Jalapeño VM implementiert einen eigenen Scheduler auf AIX Pthreads (siehe 5.3.1).